AMD Strix Halo eli AMD Ryzen AI Max+ 395 yhdessä 128GB muistin kanssa on oiva ajoalusta suurempienkin kielimallien ajamiseen. Strix Halosta saa laitteen, jossa voi osoittaa 96 GB muistia GPU:lle kielimallin käyttöön. Koska tässä on edelleen kyse PC:stä, voi laitetta käyttää niin Linuxin kuin Windowsin kanssa. Kielimallien ajoon paras yhdistelmä lienee tällä hetkellä Ubuntu Linux 24.04 + Rocm 7.0-ohjelmisto sekä vLLM itse kielimallien ajamiseen,
Strix Halo-laitteita saa pöytätyöasemana useammaltakin toimittajalta. Frame.Work on myynyt omaa laitettaan jo toista kuukautta, mutta Minisforumin uusi MS-S1 MAX on tullut myyntiin juuri uutena vaihtoehtona Frame.Workille. Frame.Work "barebone" ilman SSD-levyjä maksaa 2359 eur. Toisaalta Minisforumin saa muutaman päivän ajan 200 eur alennuksella kokonaishintaan 2199 eur ja tähän sisältyy myös 2 TB:n SSD. Jos siis tehokas kokoonpano kielimallien testailuun kiinnostaa, niin nyt kannattaa toimia.
200 eur alennuksen saa seuraavalla koodilla:

 minisforumpc.eu
Frame.Workin taas saa tilattua täältä:
minisforumpc.eu
Frame.Workin taas saa tilattua täältä:

 frame.work
Tästä artikkelista saa käsitystä mihin Strix Halo pystyy:
frame.work
Tästä artikkelista saa käsitystä mihin Strix Halo pystyy:
 www.phoronix.com
Edit:
www.phoronix.com
Edit:
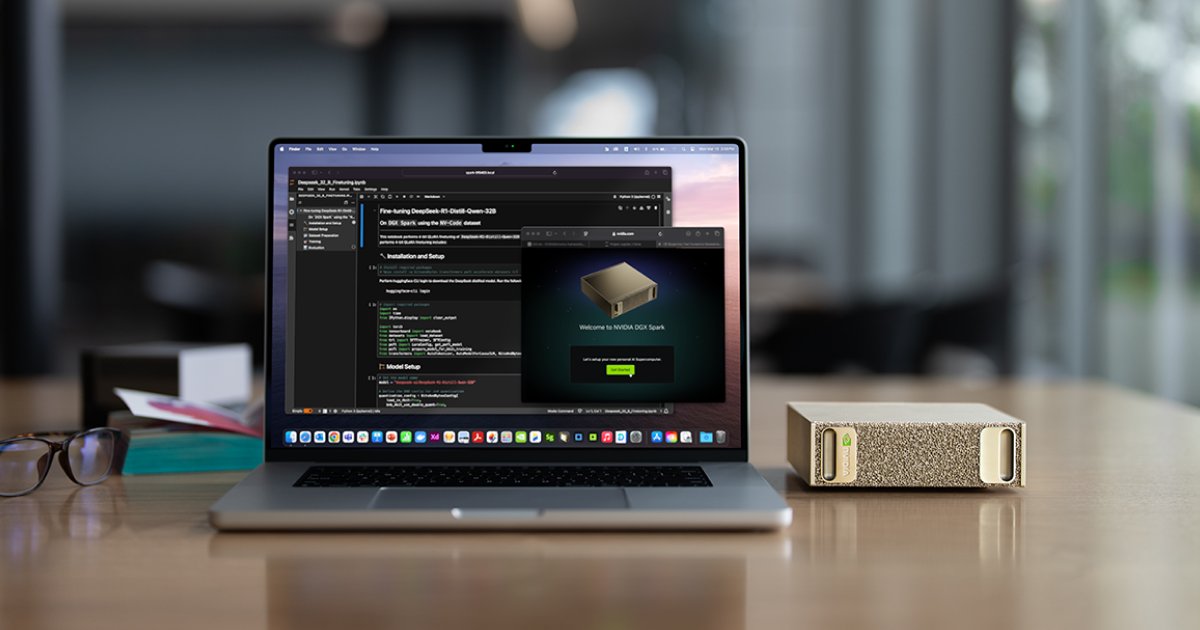
Kotikäyttöön budjetiltaan sopivia ratkaisuja, joissa voi ajaa yhtä suuria kielimalleja ei ole markkinassa järin paljon saatavilla. Strix Halon lisäksi on ainakin Nvidian DGX Spark, jonka ilmoitettu hinta USA:ssa on luokkaa 4000$. Toimitukset eivät ole vielä alkaneet ja suorituskykytestejä ei ole saatavilla. DGX Halo on ARM-prosessoreihin perustuva alusta, joka käyttää omaa sille tehtyä Linux-jakelua.
Strix Halo-laitteita saa pöytätyöasemana useammaltakin toimittajalta. Frame.Work on myynyt omaa laitettaan jo toista kuukautta, mutta Minisforumin uusi MS-S1 MAX on tullut myyntiin juuri uutena vaihtoehtona Frame.Workille. Frame.Work "barebone" ilman SSD-levyjä maksaa 2359 eur. Toisaalta Minisforumin saa muutaman päivän ajan 200 eur alennuksella kokonaishintaan 2199 eur ja tähän sisältyy myös 2 TB:n SSD. Jos siis tehokas kokoonpano kielimallien testailuun kiinnostaa, niin nyt kannattaa toimia.
200 eur alennuksen saa seuraavalla koodilla:
Minisforum MS-S1 MAX
Minisforum MS-S1 MAX Powered by AMD Ryzen™ AI Max+ 395, integrating Zen5 CPU, RDNA 3.5 GPU, and a next-gen NPU. With 16 cores and 32 threads delivering RTX 4070 Laptop-level GPU performance plus 50 TOPS NPU acceleration, it achieves more efficient AI inference.
Configure Framework Desktop DIY Edition (AMD Ryzen™ AI Max 300 Series)
Choose from AMD and Intel system options, select your preferred memory and storage, operating system, and more customizations. Available in DIY and pre-built configurations.
frame.work
AMD Ryzen AI Max+ "Strix Halo" Performance With ROCm 7.0 - Phoronix
www.phoronix.com
Kotikäyttöön budjetiltaan sopivia ratkaisuja, joissa voi ajaa yhtä suuria kielimalleja ei ole markkinassa järin paljon saatavilla. Strix Halon lisäksi on ainakin Nvidian DGX Spark, jonka ilmoitettu hinta USA:ssa on luokkaa 4000$. Toimitukset eivät ole vielä alkaneet ja suorituskykytestejä ei ole saatavilla. DGX Halo on ARM-prosessoreihin perustuva alusta, joka käyttää omaa sille tehtyä Linux-jakelua.
Viimeksi muokattu:









