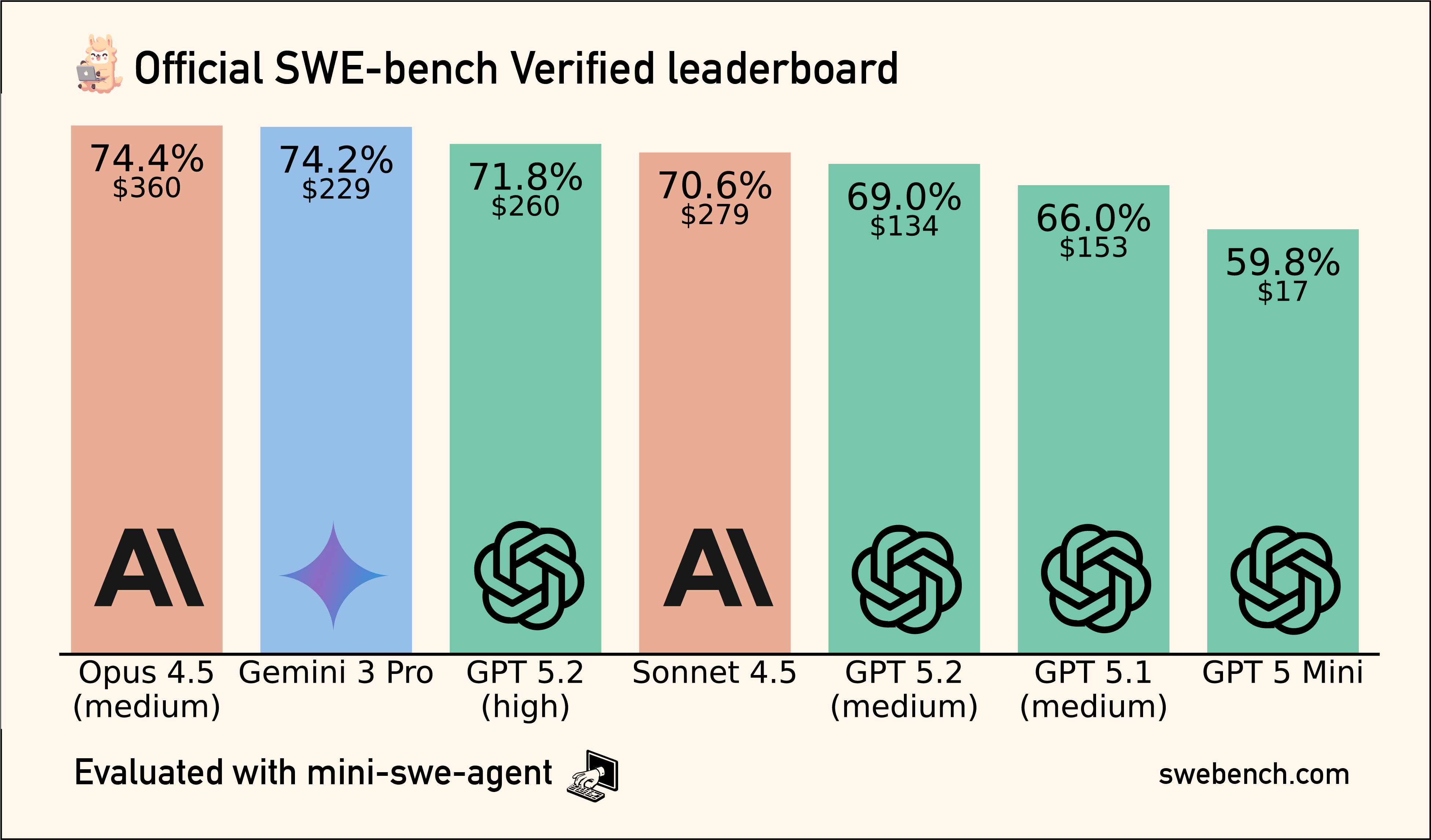
Nyt alkaa silmät painaa liikaa ja liikaa infoa näihin tunteihin mun pienille avoille, ni mä harrastan viikonloppuna lisääOn niissä paljon eroja jopa samankin mallin sisällä. Esim. clauden uusin opus niin sitä voi ajaa erilaisilla määrillä "työtä". Suosittelevat, että isoihin taskeihin/suunnitteluun high ja kun on palasteltu niin medium:lla toteutusta. Kuvassa opus 4.5 mallin suorituskyky swe-bench:ssa eri "työ" parametrilla.
Eri työkaluista kun käyttää malleja niin asetuksia on voitu optimoida eri tavalla(kontekstin koko, effortti, jne). Työkalun sisässä on prompti kielimallille ja logiikka mitä/miten työkalu laittaa kontekstiin. Sama malli samoilla asetuksilla voi toimia eri tavalla työkalusta riippuen. Jopa sillä, että importtaa sairaan määrän mcp-servereitä ja työkaluja kontekstiin voi myrkyttää mallin osaamisen ja käytettävien tokeneiden määrä kuuhun==kallista.
Ei olla vielä semmoisessa "it just works" ajassa. Jos/kun joku ei onnistu niin voi katsella, että toimisko eri mallilla/eri tavalla homman alustamalla vai onko vielä tekemätön paikka AI:lle.

 varsinkin ko si nähny kuinka yö automatio nyt toiminut fiksausten jälkeen
varsinkin ko si nähny kuinka yö automatio nyt toiminut fiksausten jälkeenEdit toki siinä tehdesaäkin huomasin et ohitti välillä koko koodin ja keskittyi vain juuri ongelmaan, ja piti ohjeistaa palauttamaan koko kokonaisuus. Mut se oli helpoa. Niin ja sillon ollu viellä got repoa, ihan filua luki ja chatissa annoin jsonia node rediltä. Ni paikkas siis vaan yhen ongelman yksin ja muut toiminnot siis jäi pois, mut kun huomautti tuntui tulevan toimiva kokonaisuus
Viimeksi muokattu: